The average number of unique states visited by AlphaZero and Go-Exploit
Por um escritor misterioso
Descrição
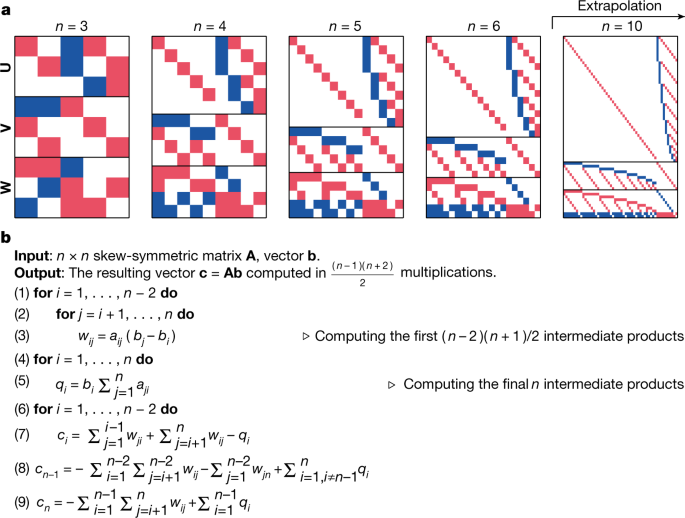
Discovering faster matrix multiplication algorithms with reinforcement learning
Applied Sciences, Free Full-Text
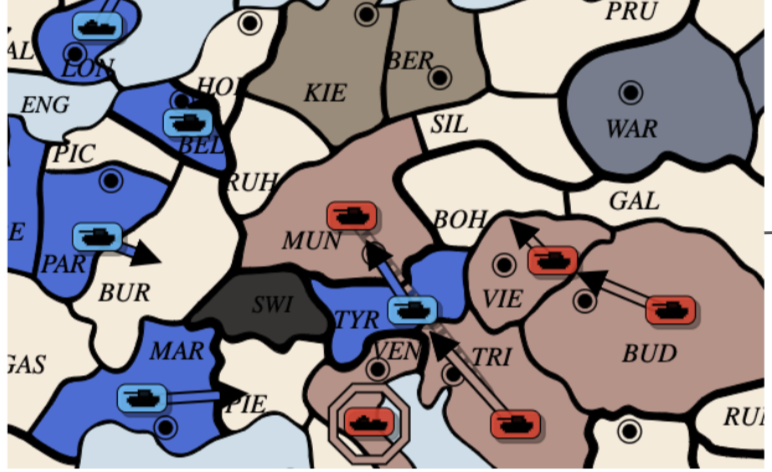
2110.02924] No-Press Diplomacy from Scratch
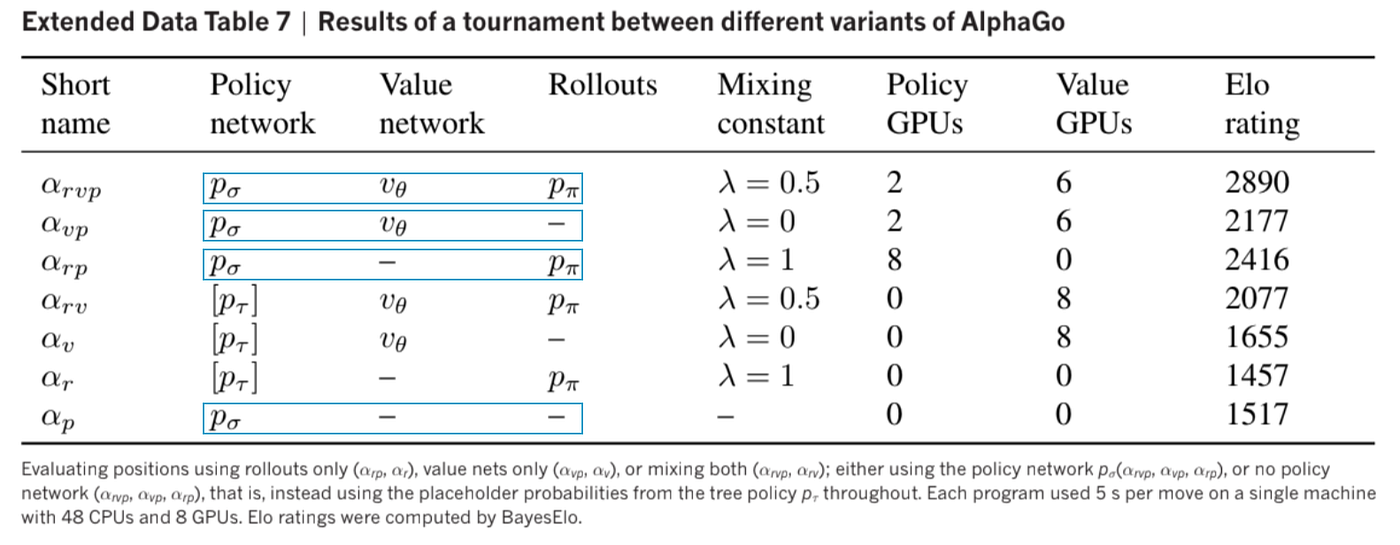
AlphaGo: How it works technically?, by Jonathan Hui
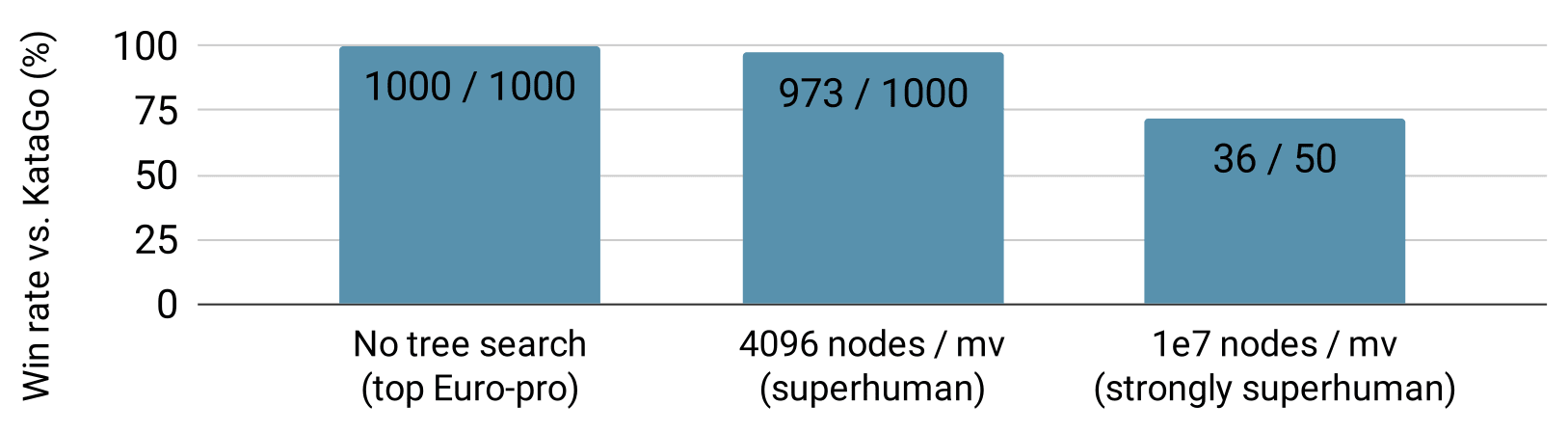
Even Superhuman Go AIs Have Surprising Failure Modes — LessWrong
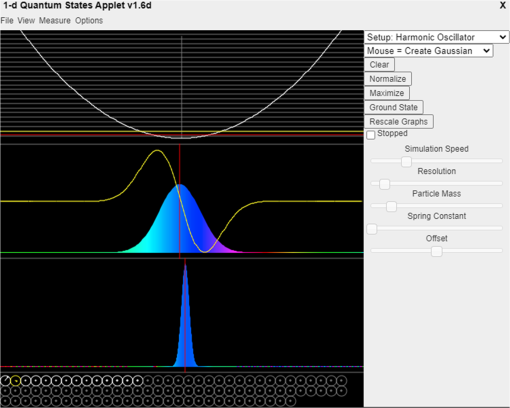
Quantum games and interactive tools for quantum technologies outreach and education
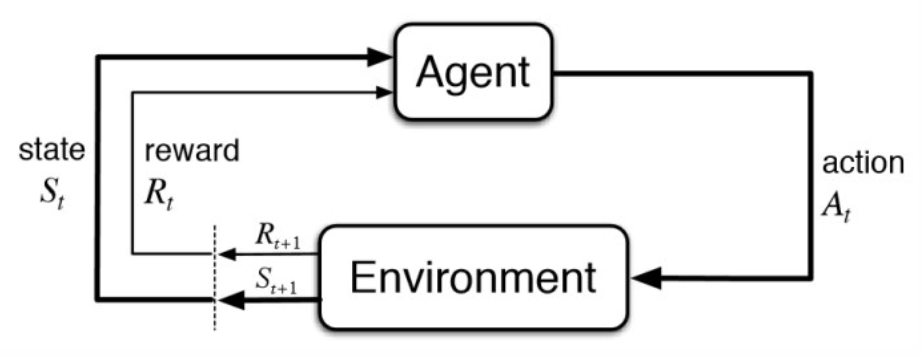
The Evolution of AlphaGo to MuZero, by Connor Shorten
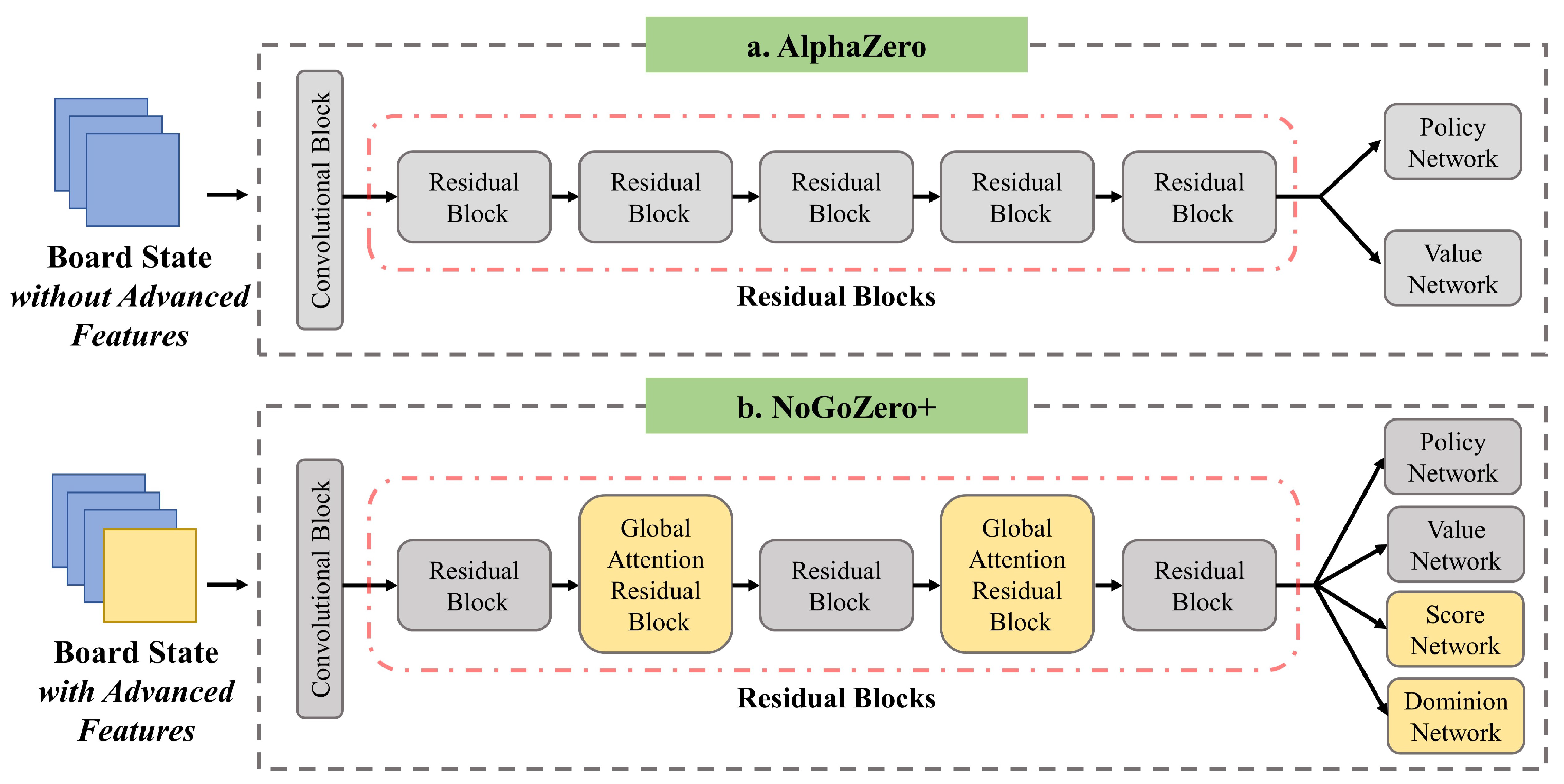
Electronics, Free Full-Text

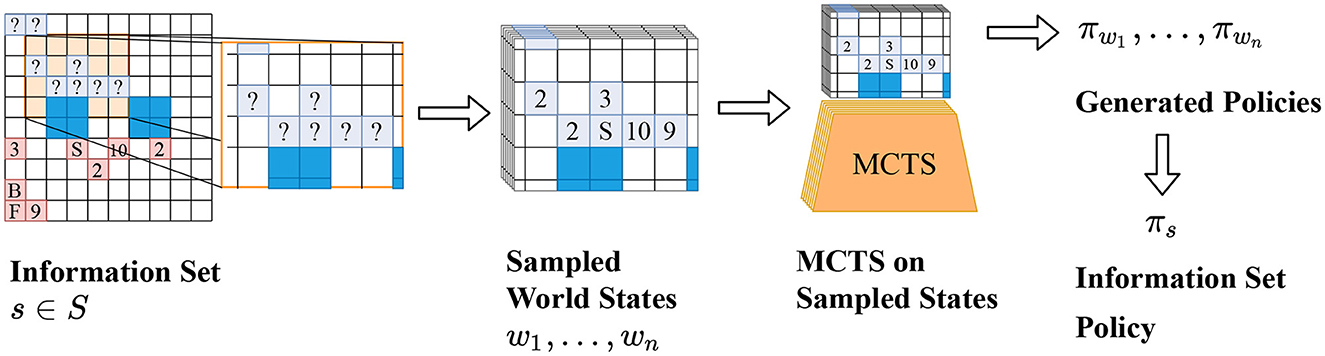
Student of Games: A unified learning algorithm for both perfect and imperfect information games

AlphaGo Zero: Mastering the Game of Go Without Human Knowledge

AlphaZero Explained · On AI
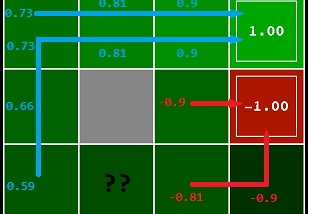
Monte Carlo in Reinforcement Learning, the Easy Way, by Ziad SALLOUM

The average number of unique states visited by AlphaZero and Go-Exploit

Automatic mechanistic inference from large families of Boolean models generated by Monte Carlo Tree Search
de
por adulto (o preço varia de acordo com o tamanho do grupo)