wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading · GitHub
Por um escritor misterioso
Descrição
This repository contains the three WikiReading datasets as used and described in WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia, Hewlett, et al, ACL 2016 (the English WikiReading dataset) and Byte-level Machine Reading across Morphologically Varied Languages, Kenter et al, AAAI-18 (the Turkish and Russian datasets). - wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading
2023 Spark xml stream the
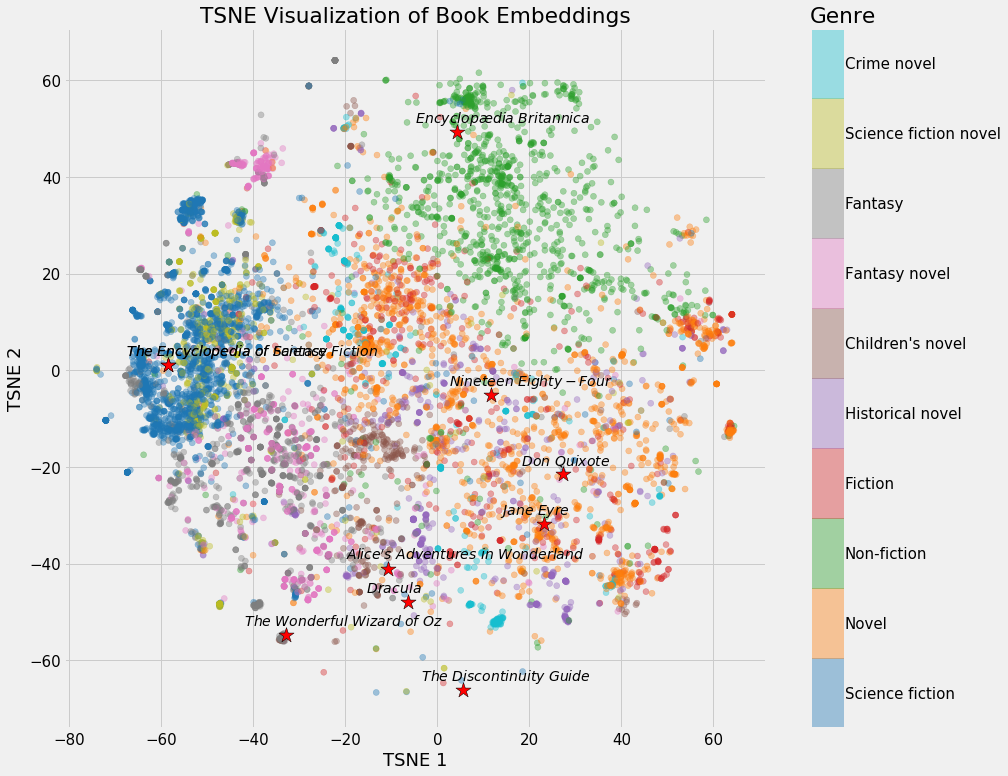
Neural Network Embeddings Explained, by Will Koehrsen

MetaPro: A computational metaphor processing model for text pre-processing - ScienceDirect

A comprehensive survey of personal knowledge graphs - Chakraborty - WIREs Data Mining and Knowledge Discovery - Wiley Online Library
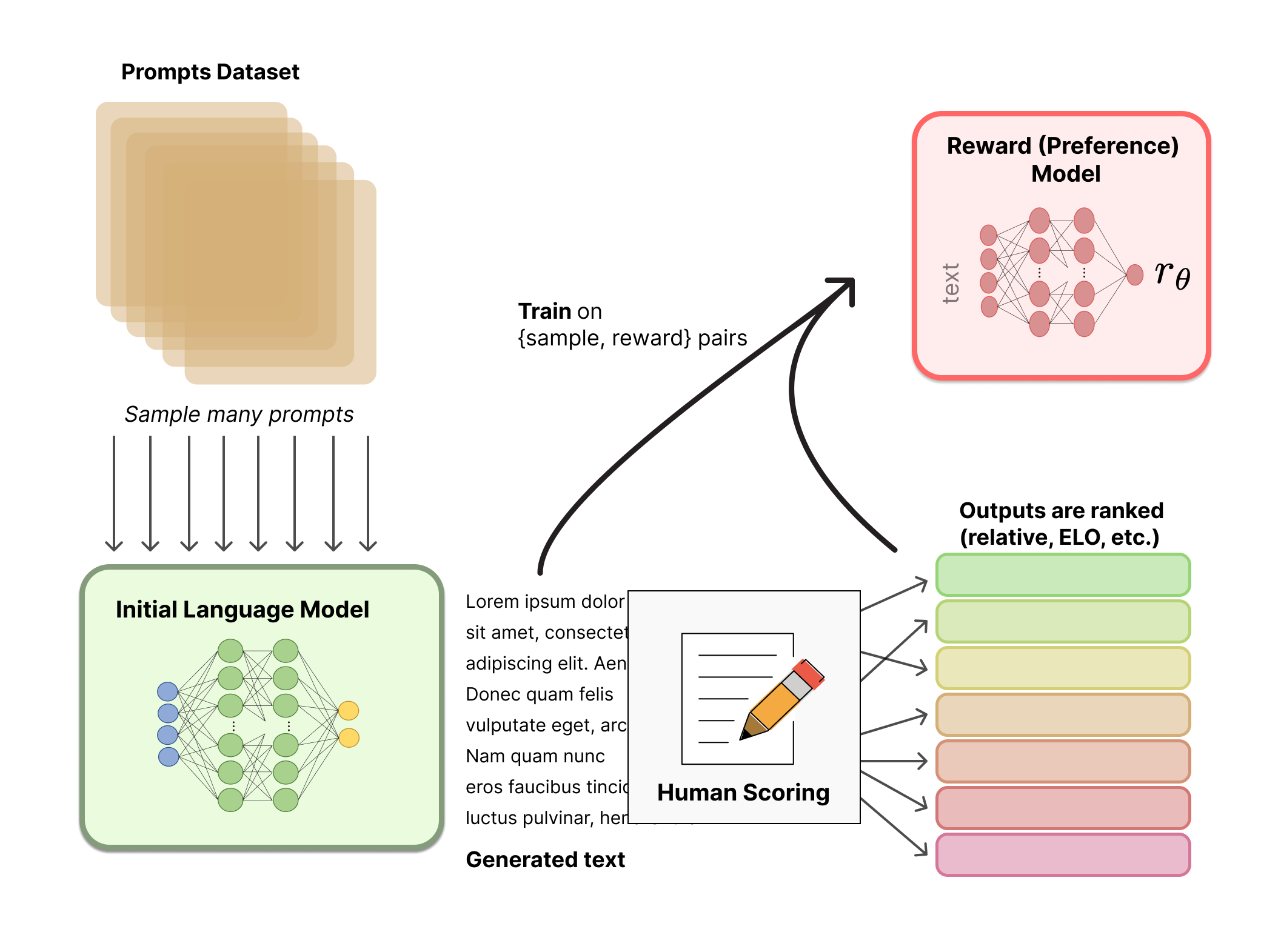
Transformer models: an introduction and catalog — 2023 Edition - AI, software, tech, and people. Not in that order. By X
GitHub - smuthubabu/awesome-public-datasets: .com/smuthubabu/awesome-public-datasets/blob/master/README.rst

Wikipedia on the CompTox Chemicals Dashboard: Connecting Resources to Enrich Public Chemical Data

French machine reading for question answering

Wikipedia on the CompTox Chemicals Dashboard: Connecting Resources to Enrich Public Chemical Data
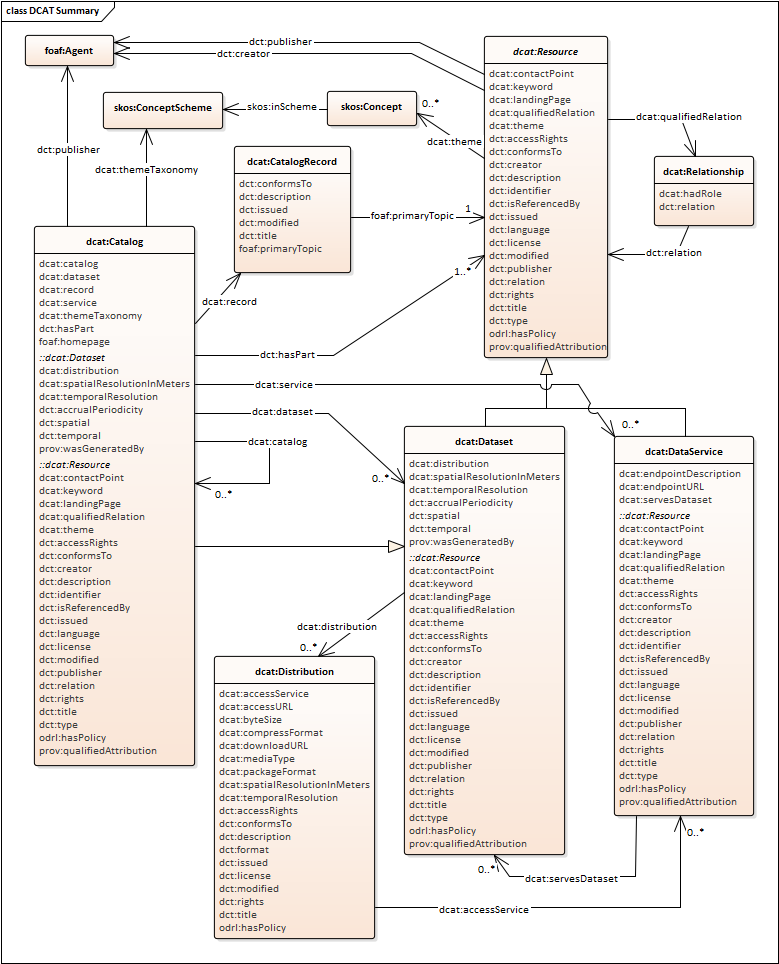
Data Catalog Vocabulary (DCAT) - Version 2
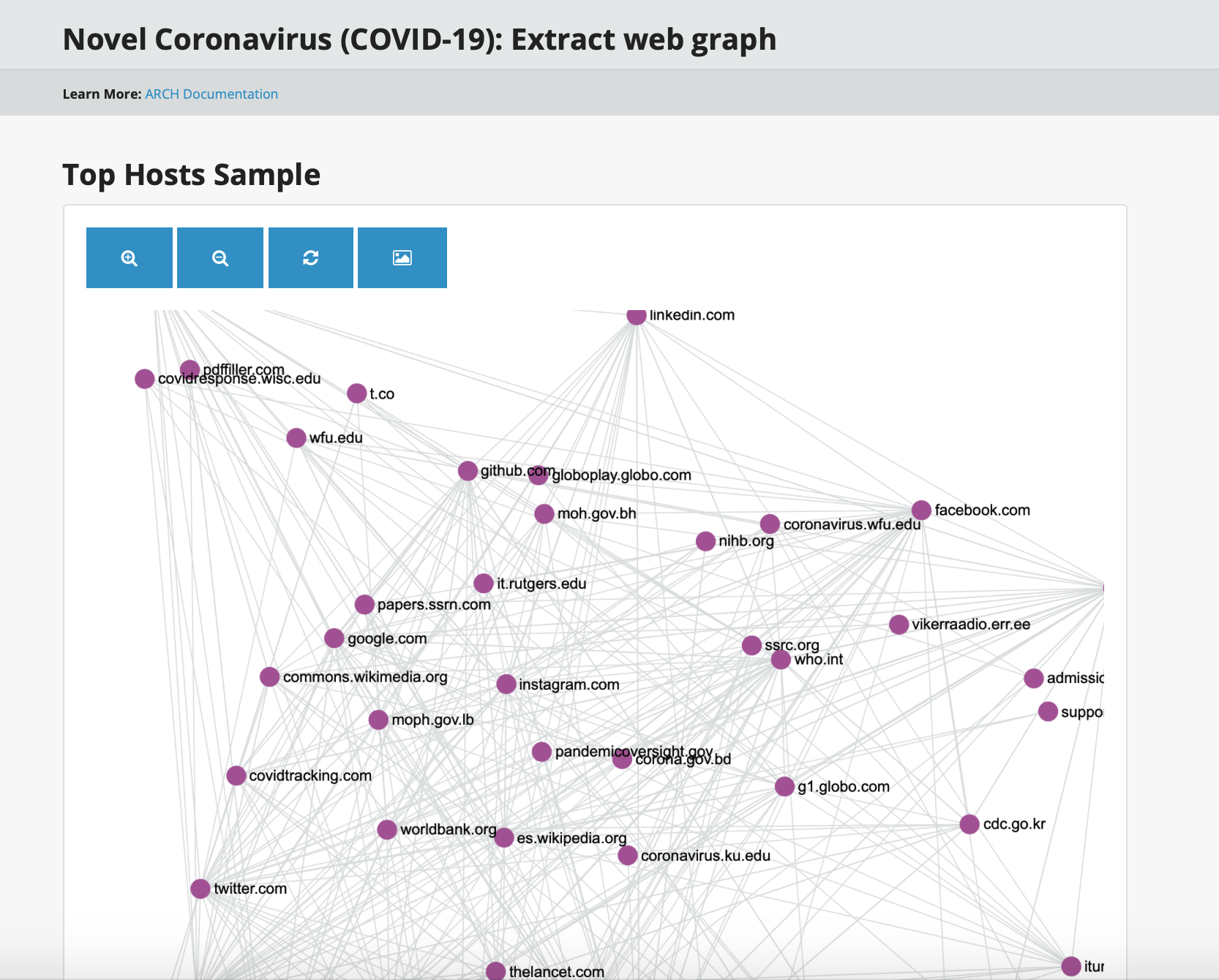
research
GitHub - google-research-datasets/WikipediaAbbreviationData: This data set consists of 24,000 English sentences, extracted from Wikipedia in 2017, annotated to support development of an abbreviation expansion system for text-to-speech synthesis (e.g.
Using natural language generation to bootstrap missing Wikipedia articles: A human-centric perspective - IOS Press

Explore informative blogs about Python

The Pile: An 800GB Dataset of Diverse Text for Language Modeling – arXiv Vanity
de
por adulto (o preço varia de acordo com o tamanho do grupo)






