vocab.txt · microsoft/git-large-coco at main
Por um escritor misterioso
Descrição
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Salesforce AI Propose A Novel Framework That Trains An Open Vocabulary Object Detector With Pseudo Bounding-Box Labels Generated From Large-Scale Image-Caption Pairs - MarkTechPost
GitHub - siwooyong/Codalab-Microsoft-COCO-Image-Captioning-Challenge: 🥉 Codalab-Microsoft-COCO-Image-Captioning-Challenge 3rd place solution(06.30.21)
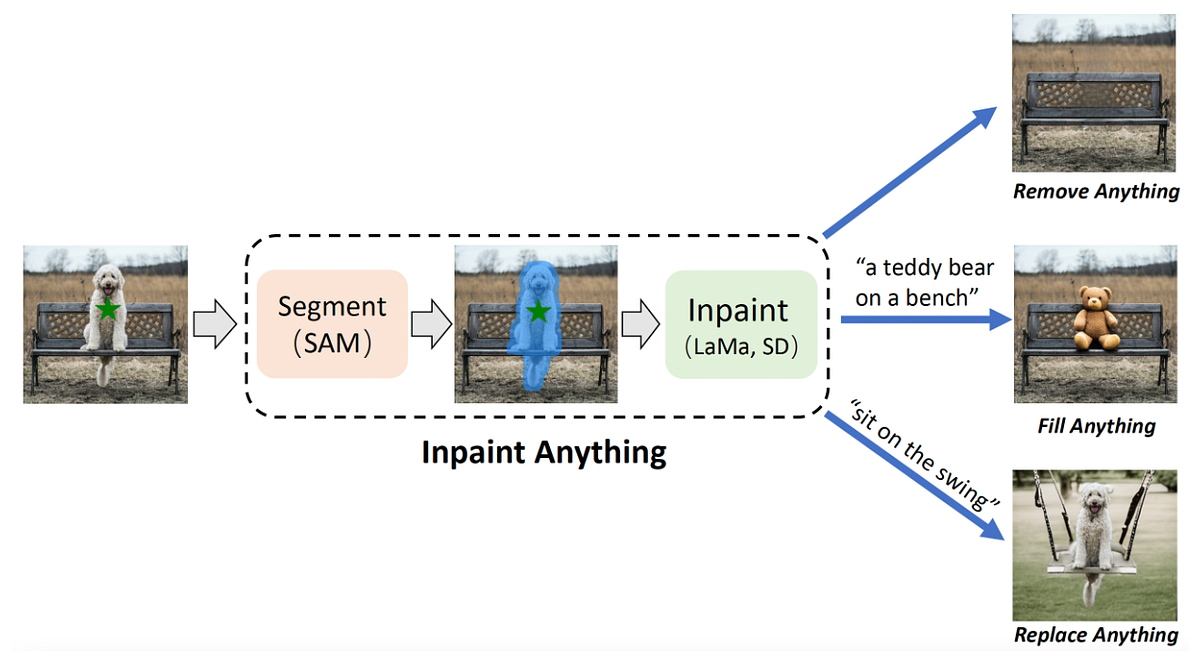
This (longer) week in multimodal ai art (14/Jun - 24/Jun)
List of Large Language Vision Models, by Sung Kim

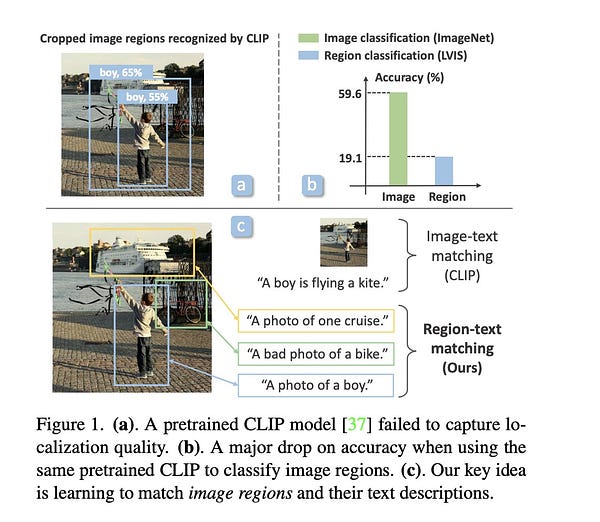
Object Detection in the Wild via Grounded Language Image Pre-training - Microsoft Research
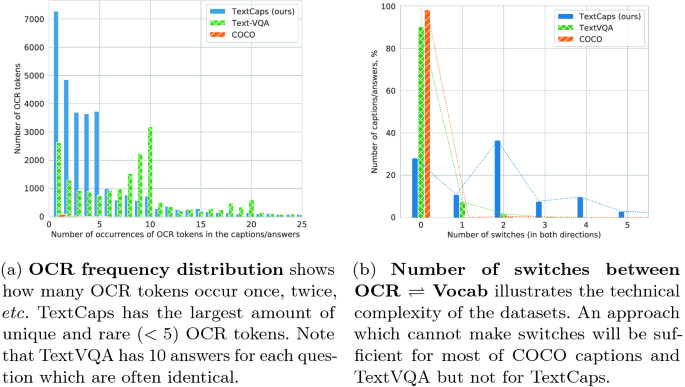
TextCaps: A Dataset for Image Captioning with Reading Comprehension
Machine Learning – Lucky's Notes
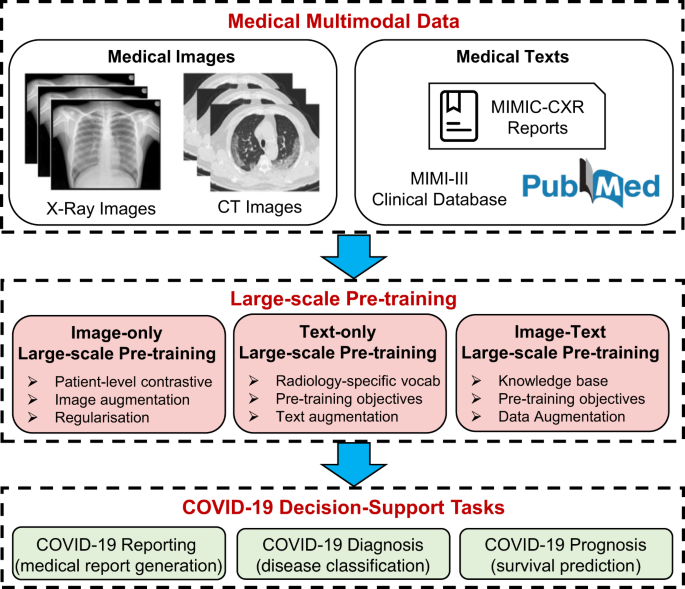
A medical multimodal large language model for future pandemics

PDF) Learning to Answer Visual Questions from Web Videos

RxnScribe: A Sequence Generation Model for Reaction Diagram Parsing
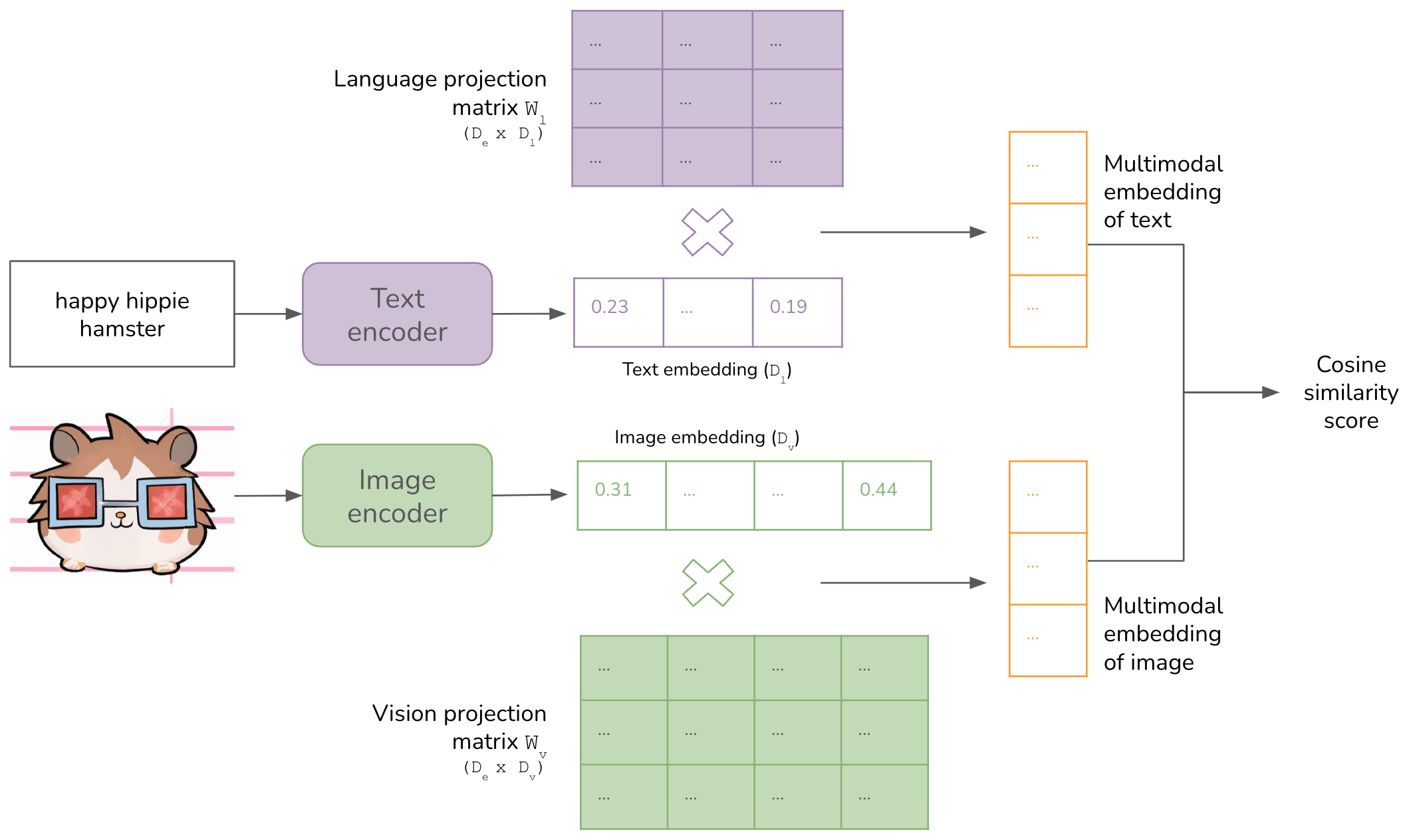
Multimodality and Large Multimodal Models (LMMs)
Image-text classification using foundation models

Build and Play! Your Own V&L Model Equipped with LLM!, by Yuichi Inoue

Copy‐paste with self‐adaptation: A self‐adaptive adjustment method based on copy‐paste augmentation - Yu - IET Computer Vision - Wiley Online Library

Panoptic Segmentation
de
por adulto (o preço varia de acordo com o tamanho do grupo)






